Talker-specific perceptual adaptation to second-language speech-in-noise: Tuning-in to the talker while tuning-out the noise
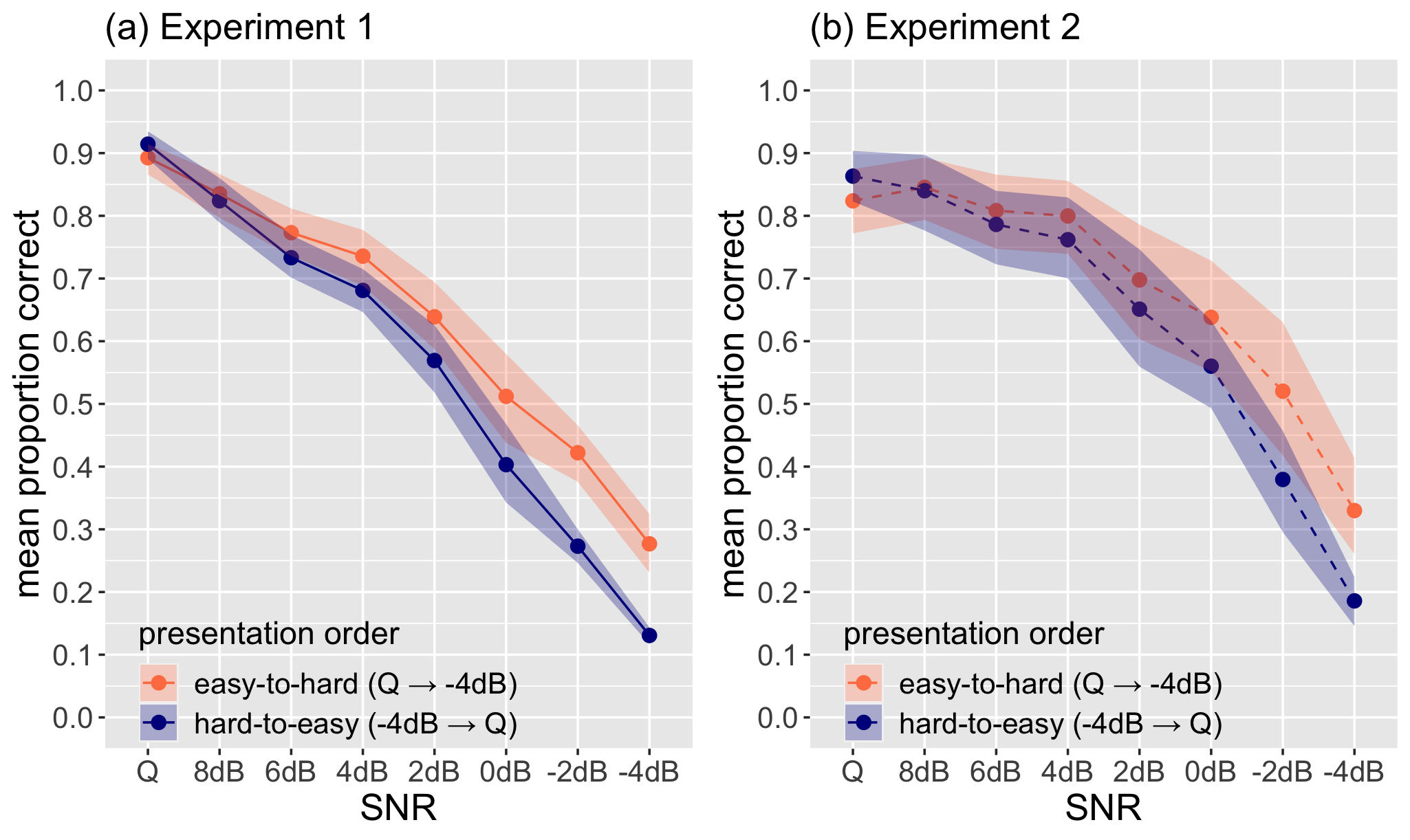
When listeners encounter a difficult-to-understand talker in a challenging listening environment, their perceptual mechanisms can adapt, making the talker easier to understand. This study examined talker-specific perceptual adaptation by embedding speech from second-language (L2) English talkers in varying levels of noise and collecting transcriptions from first-language English listeners. Across four experiments, we found that both tuning-in to the talker (learning the talker’s acoustic and articulatory patterns, facilitated by training without noise) and tuning-out the noise (learning to separate target speech from noise, facilitated by training with extremely high levels of noise) contribute to talker-specific perceptual adaptation to L2 speech in noise.
Predicting relative intelligibility of second-language (L2) talkers using self-supervised representations
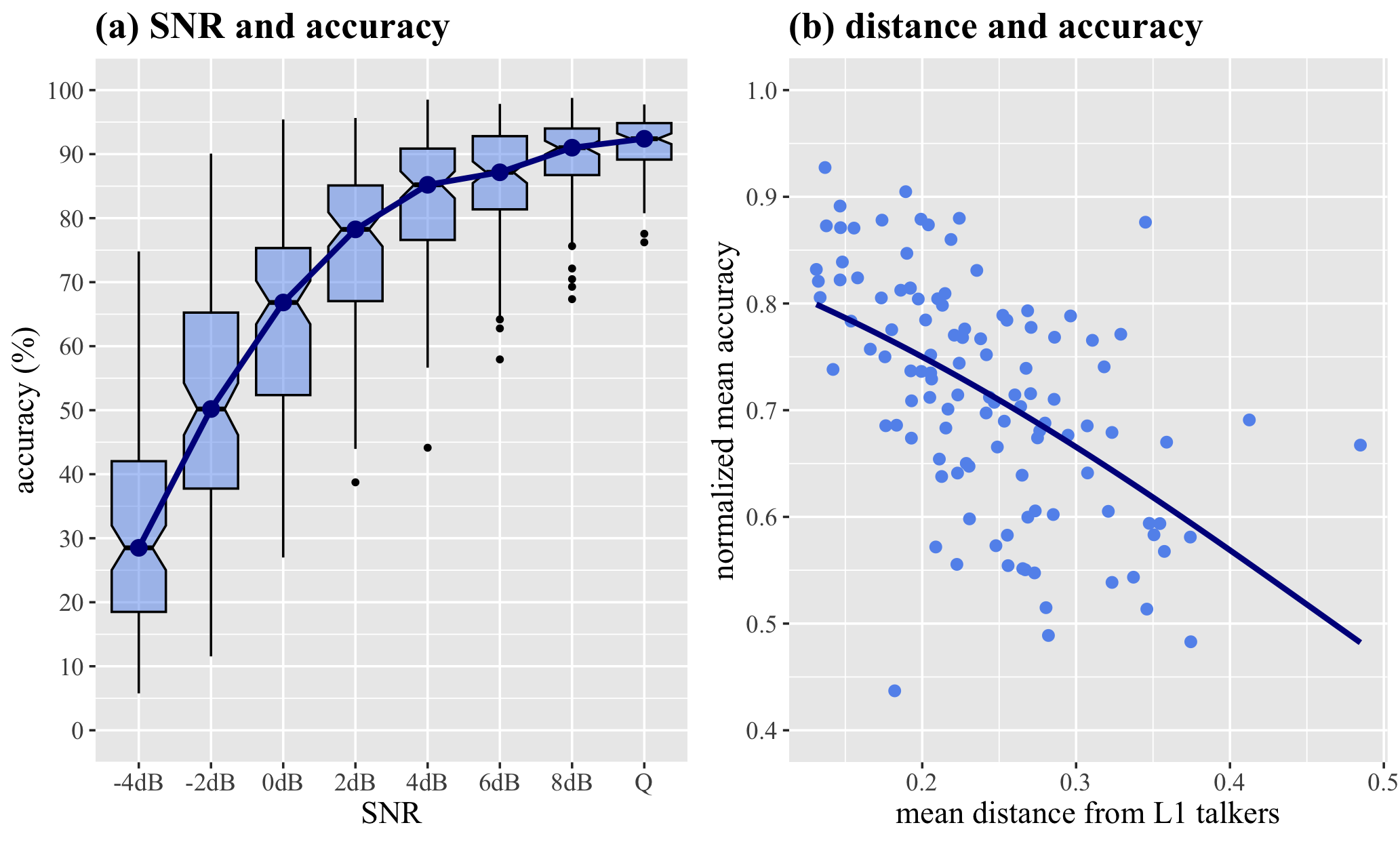
In this study, we modeled relative speech intelligibility of over 100 L2 English talkers, using a self-supervised learning model.
For each recording, we obtained representations from a self-supervised model, which formed a trajectory in the perceptual similarity space. We found that the average distance of the trajectories
of an L2 talker from the L1 talker group correlates with their intelligibility assessed by human L1 listeners.
Notably, the distance measure predicted the relative intelligibility of L2 talkers more robustly than traditional acoustic-phonetic cues (e.g., speech rate, mean pitch).
This study emphasizes the importance of holistic assessment of speech in modeling speech intelligibility.
Automatic recognition of L2 speech-in-noise
In this study, we compared four state-of-the-art Automatic Speech Recognition (ASR) systems (Google, HuBERT, wav2vec 2.0, whisper) and human listeners on word recognition accuracy of second-language (L2) speech embedded in noise.
We found that one system, whisper, performed at levels similar to (or in some cases, better than) human listeners.
However, the content of its responses diverged substantially from human responses, when speech was embedded in high levels of noise.
This suggests that ASR could be utilized to predict human intelligibility but should be used with caution.
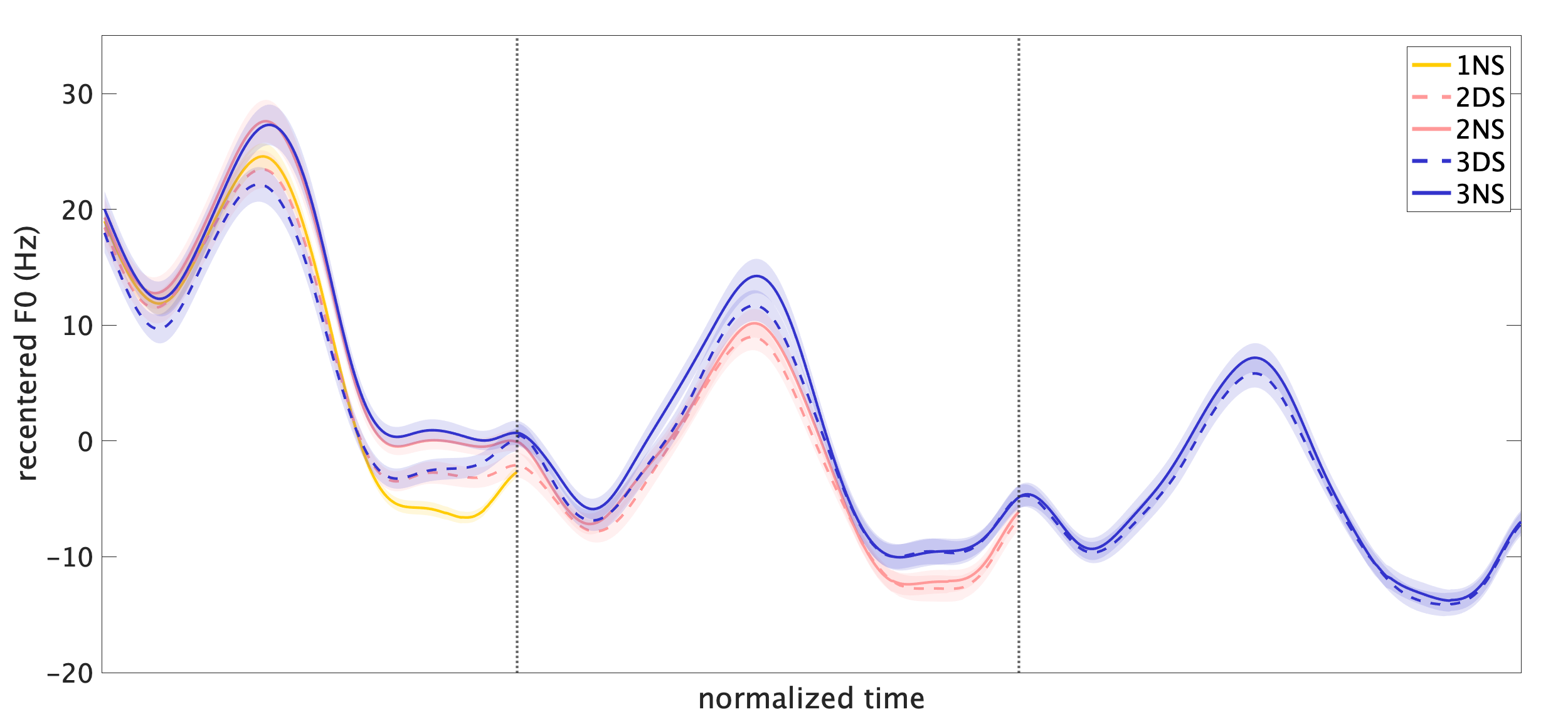
Proactive and reactive F0 adjustments in speech
A production experiment was conducted to investigate speakers' (i) proactive and (ii) reactive F0 control.
In particular, the experiment examined whether speakers vary F0 parameters (i) according to the initially planned utterance length and (ii) in response to the unanticipated changes in the length.
An experimental paradigm was developed in which the visual stimuli that cue the parts of the utterance are delayed until after participants initiate an utterance.
Analyses of F0 trajectories found evidence for both proactive and reactive F0 control.
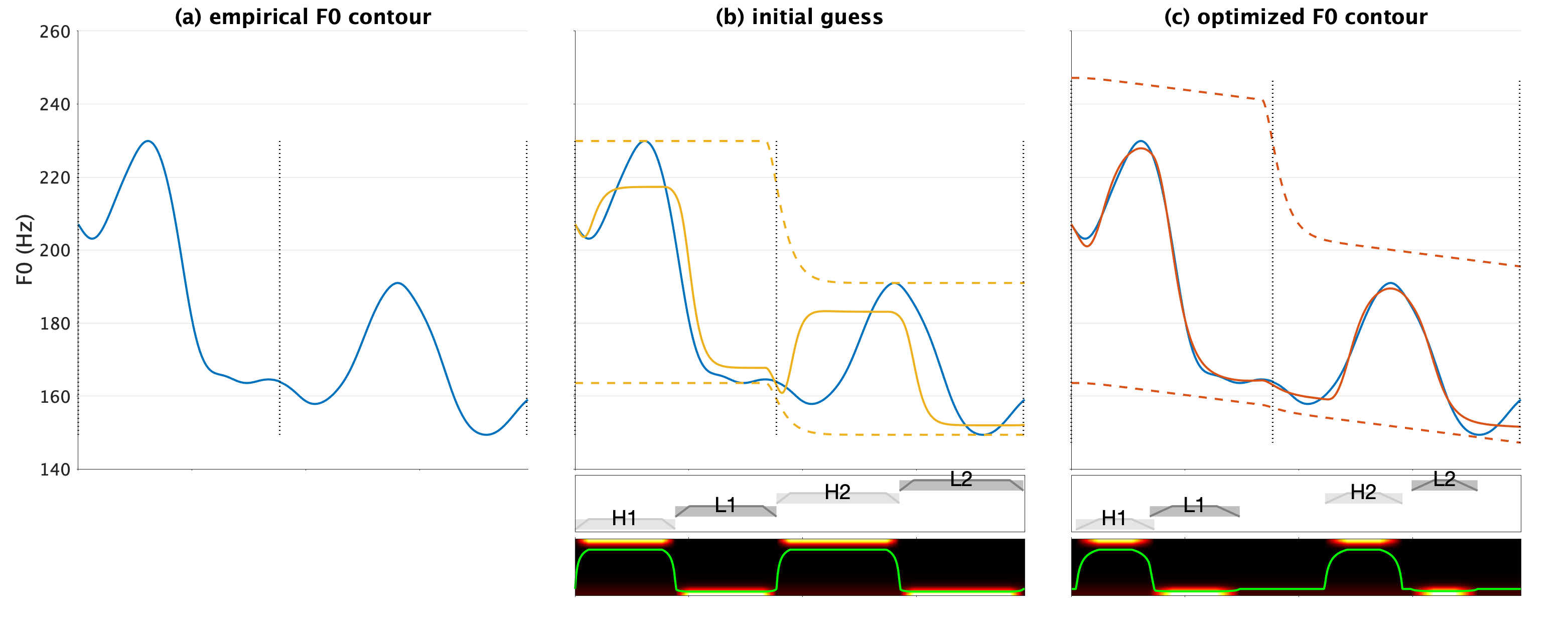
The Gesture-Field-Register framework for modeling F0 control
This study proposed a modeling framework that accounts for speakers' pitch/F0 control, building on Articulatory Phonology and Task Dynamics. The framework considers F0 gestures to be the fundamental control units.
The F0 gestures have normalized targets; at each time point, the targets of the gestures that are active and the forces of the neutral system determine the (normalized) dynamic target of the F0 tract variable.
The dynamic targets are transformed to F0 values in Hz via F0 register parameters.
By fitting empirical F0 data that span multiple phrases (with several F0 peaks/valleys), we found evidence in support of the control mechanism, where speakers have invariant F0 targets but variant F0 register.
This suggests that speakers may be primarily adjusting their F0 space with relatively fixed F0 targets, in order to produce F0 variations within an utterance.
Functional relations between speech rate and phonetic variables
This study examined how phonetic measures covary with speech rate, specifically assessing whether there is evidence for linear and/or non-linear relations with rate, and how those relations may differ between phrase boundaries.
Productions of English non-restrictive (NRRCs) and restrictive relative clauses (RRCs) were collected using a method in which variation in speech rate was cued by the speed of motion of a visual stimulus.
Analyses of articulatory and acoustic variables showed that the variables associated with a phrase boundary that follows the RC were more susceptible to rate variation than those at a boundary that precedes the RC.
Phonetic variables at the post-RC boundary also showed evidence for non-linear relations with rate, which suggest floor or ceiling attenuation effects at extreme rates.
